|
Jiaming Zhou I am a third-year PhD student at Hong Kong University of Science and Technology, Guangzhou, under the supervision of Prof. Junwei Liang. Prior to this, I obtained my Bachelor's degree in Computer Science and Engineering, from Sichuan University in 2020. Then I received my Master degree in Computer Science and Engineering, at Sun Yat-Sen University in 2023, where I was advised by Prof. Wei-Shi Zheng. I'm interested in computer vision and robotics. Currently, I mainly focus on generalizable robotic manipulation, embodied world model. I am looking for a research internship. If you have suitable opportunities, please feel free to contact me. |

|
| ❅ 09/2025: One paper was accepted to NeurIPS 2025. [Generalizable Cross-task Manipulation] |
| ❅ 08/2025: Two papers were accepted to CoRL 2025. [GLOVER++], [Omni-Perception] |
| ❅ 03/2025: One paper was accepted to CVPR 2025. [Human-Robot Alignment] [量子位] |
| ❅ 09/2024: One paper was accepted to CoRL 2024. [Contrastive Imitation] |
| ❅ 07/2024: One paper was accepted to TPAMI. [HCTransformer] |
| ❅ 03/2024: Releasing the first cross-domain open-vocabulary action recognition benchmark! [XOV-Action] |
| ❅ 12/2023: AdaptFocus for long-video action understanding was released. [AdaptFocus] |
| ❅ 09/2023: One paper was accepted to NeurIPS 2023. [STDN] |
| ❅ 08/2023: One paper was accepted to TMM 2023. [TwinFormer] |
| ❅ 07/2022: One paper was accepted to ECCV 2022. [Cycle Inconsistency] |
| ❅ 03/2021: One paper was accepted to CVPR 2021. [GHRM] |

|
Exploring the Limits of Vision-Language-Action Manipulations in Cross-task Generalization
Jiaming Zhou, Ke Ye, Jiayi Liu, Teli Ma, Zifan Wang, Ronghe Qiu, Kun-Yu Lin, Zhilin Zhao, Junwei Liang NeurIPS, 2025 [paper] [bibtex] [project page] A cross-task manipulation generalization benchmark to evaluate existing Vision-Language-Action (VLA) models and a novel generalizable VLA method. |
|
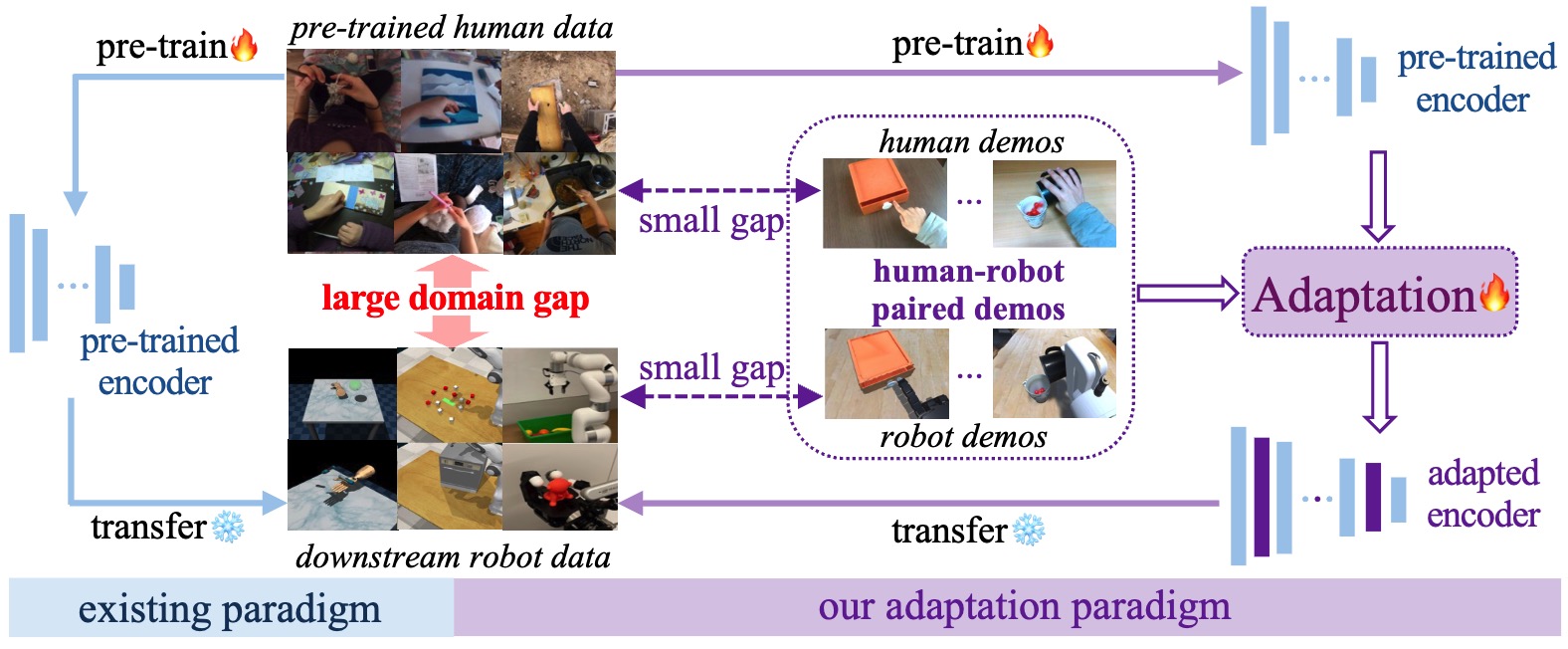
Mitigating the Human-Robot Domain Discrepancy in Visual Pre-training for Robotic Manipulation
Jiaming Zhou, Teli Ma, Kun-Yu Lin, Zifan Wang, Ronghe Qiu, Junwei Liang CVPR, 2025 [paper] [bibtex] [project page] [量子位] A new paradigm utilizing paired human-robot videos to adapt human-data pretrained foundation models to robotic manipulation domain. |

|
From Watch to Imagine Steering Long-horizon Manipulation via Human Demonstration and Future Envisionment
Ke Ye, Jiaming Zhou (co-first & project lead), Yuanfeng Qiu, Jiayi Liu, Shihui Zhou, Kun-Yu Lin, Junwei Liang arxiv, 2025 [paper] [bibtex] [project page] [深蓝具身智能] A zero-shot long-horizon manipulation framework that mimics human long-range activities via demonstrations and achieves robust execution via generating visual future. |
|
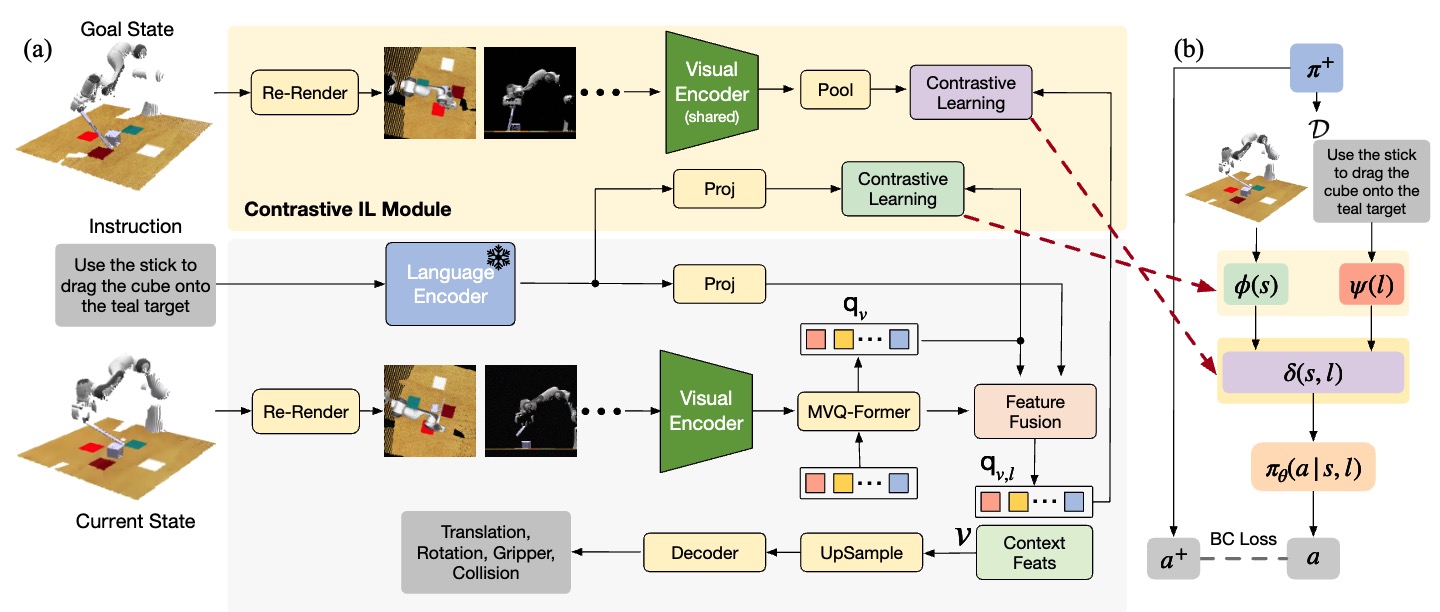
Contrastive Imitation Learning for Language-guided Multi-Task Robotic Manipulation
Teli Ma, Jiaming Zhou, Zifan Wang, Ronghe Qiu, Junwei Liang CoRL, 2024 [paper] [project page] [bibtex] |
|
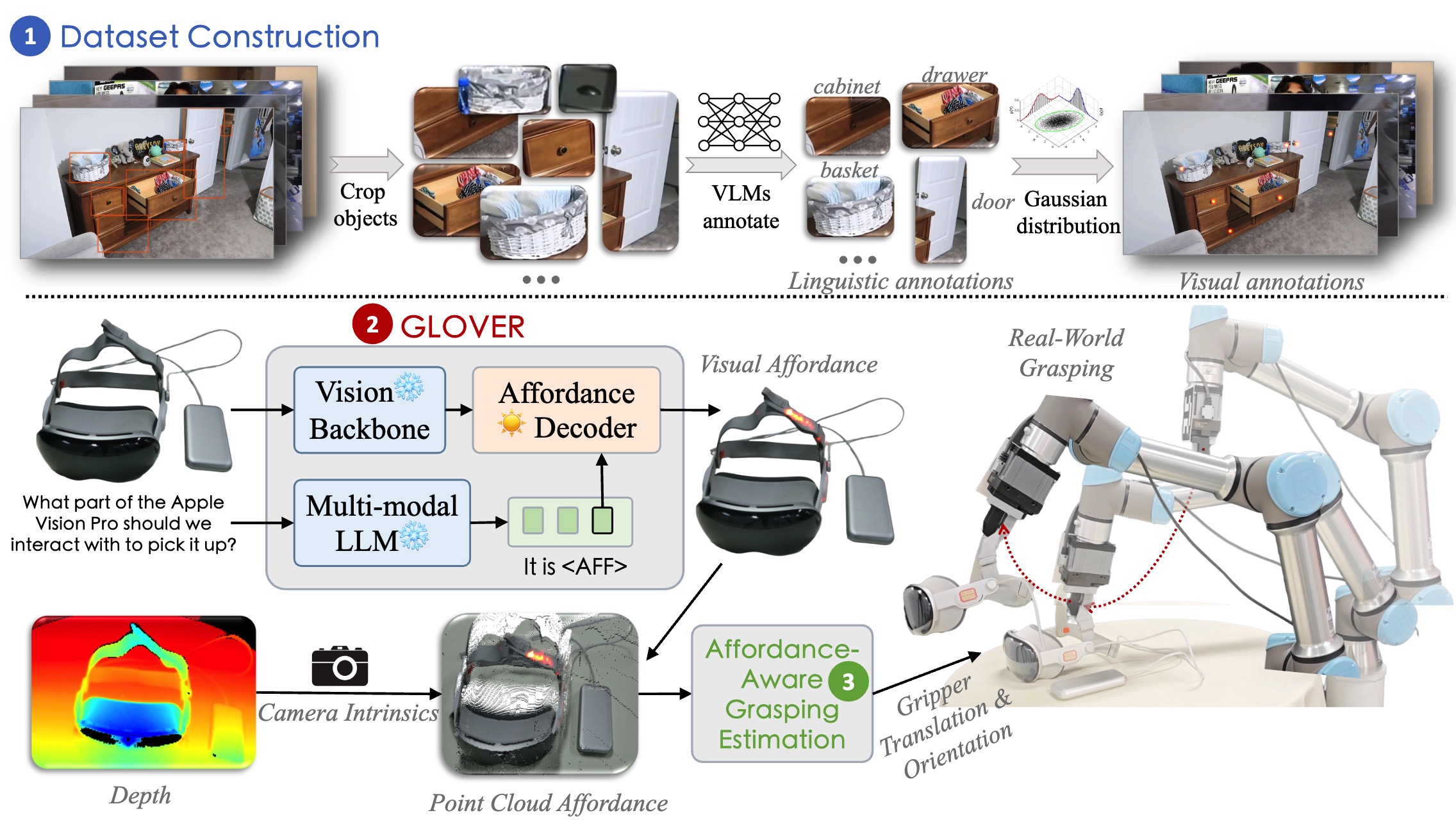
GLOVER: Generalizable Open-Vocabulary Affordance Reasoning
for Task-Oriented Grasping
Teli Ma, Zifan Wang, Jiaming Zhou, Mengmeng Wang, Junwei Liang arxiv, 2025 [paper] [project page] [bibtex] |
|
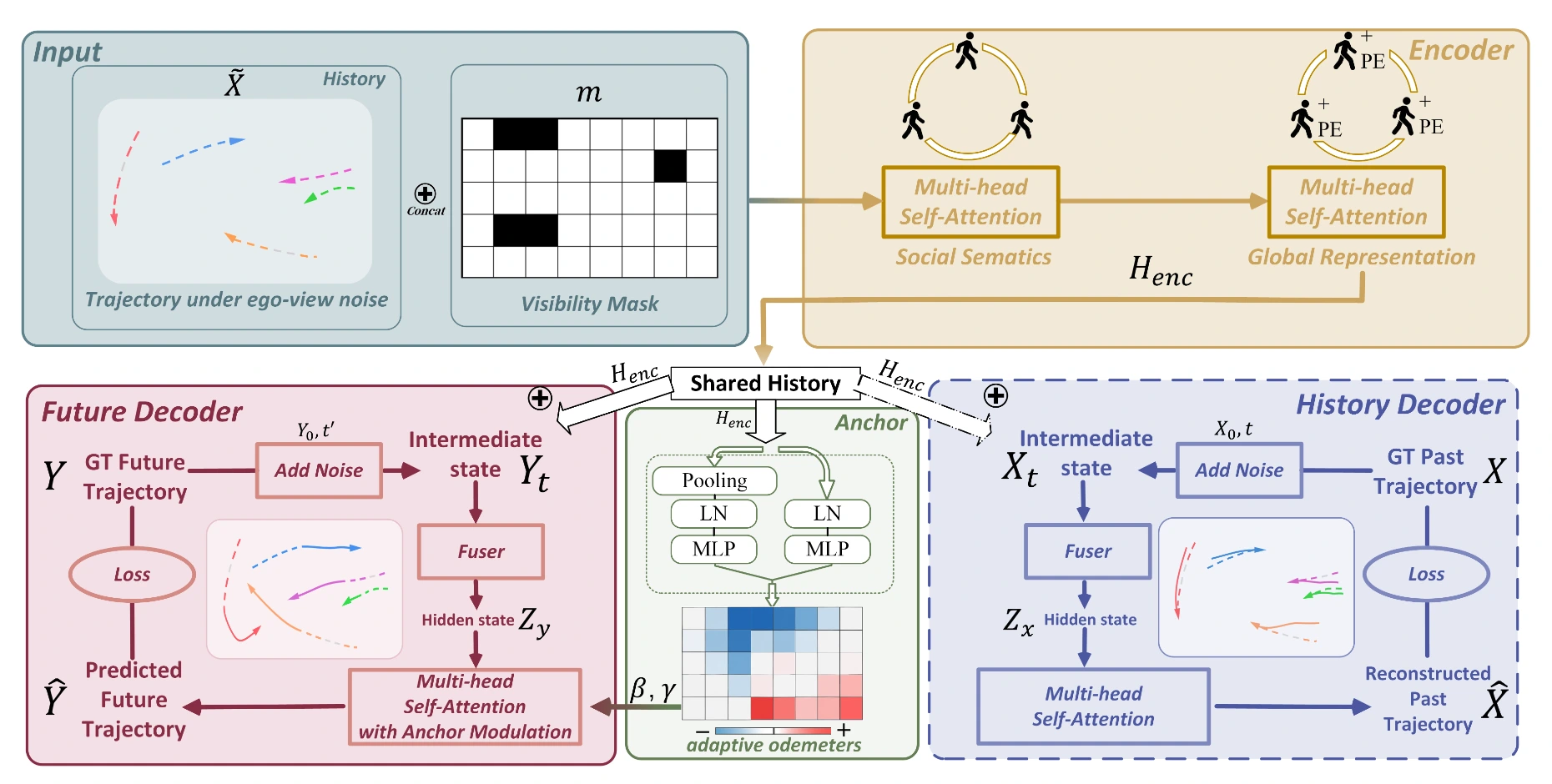
EgoTraj-Bench: Towards Robust Trajectory Prediction Under Ego-view Noisy Observations
Jiayi Liu, Jiaming Zhou, Ke Ye, Kun-Yu Lin, Allan Wang, Junwei Liang arxiv, 2025 [paper] [bibtex] |
|
Omni-Perception: Omnidirectional Collision Avoidance for Legged Locomotion in Dynamic Environments
Zifan Wang, Teli Ma, Yufei Jia, Xun Yang, Jiaming Zhou, Wenlong Ouyang, Qiang Zhang, Junwei Liang CoRL, 2025 [paper] [project page] [bibtex] |
|
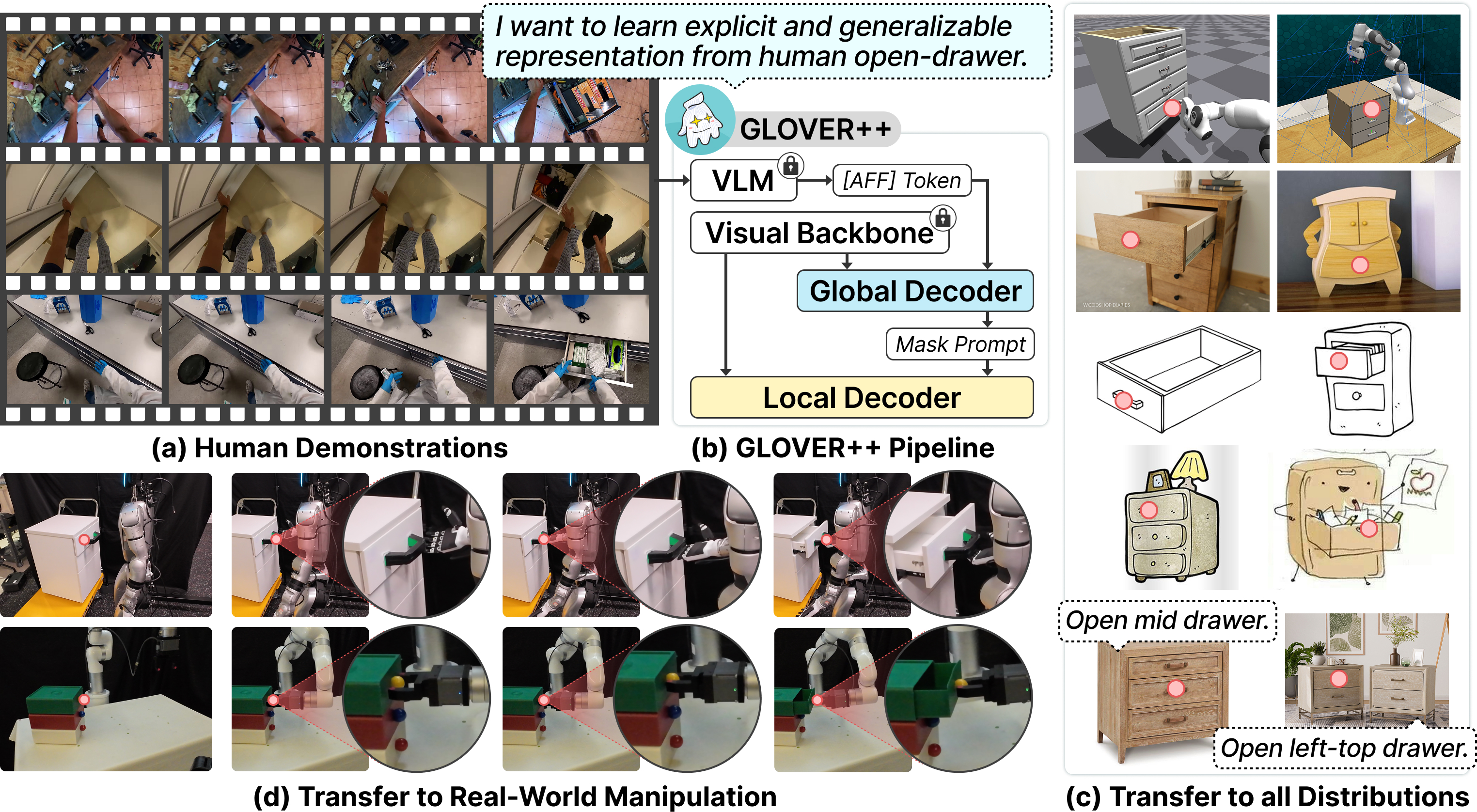
GLOVER++: Enhanced Generalizable Open-Vocabulary Affordance Reasoning for Task-Oriented Grasping
Teli Ma, Jia Zheng, Zifan Wang, Ziyao Gao, Jiaming Zhou, Junwei Liang CoRL, 2025 [paper] [project page] [bibtex] |
|
AdaFocus: Towards End-to-end Weakly Supervised Learning for Long-Video Action Understanding
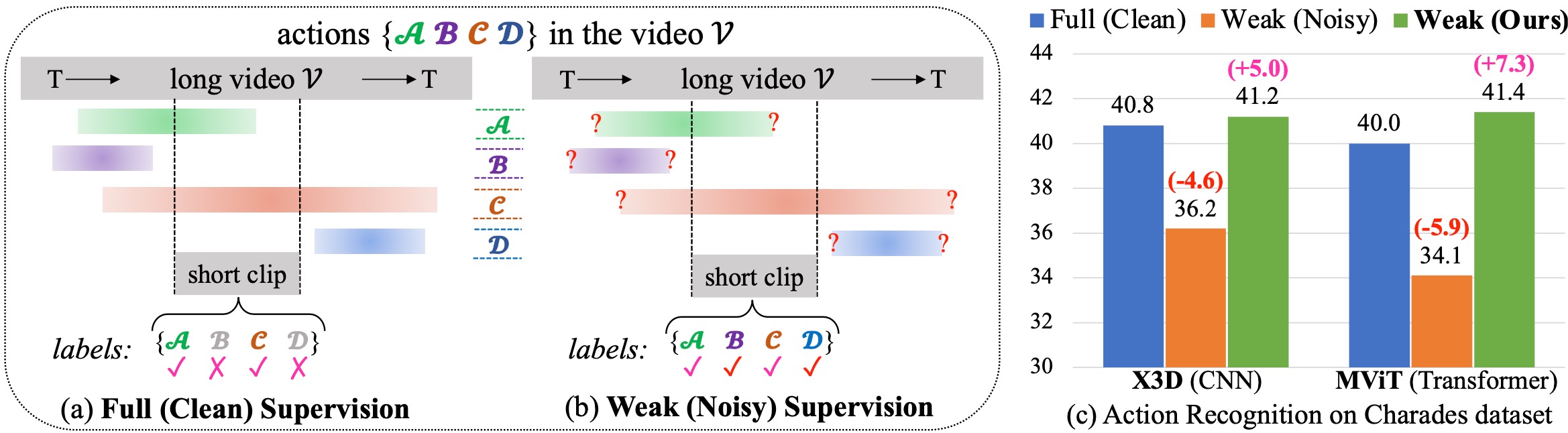
Jiaming Zhou, Hanjun Li, Kun-Yu Lin, Junwei Liang arxiv, 2024 [paper] [bibtex] [project page] The first weakly supervised framework for developing efficient end-to-end action recognition models on long videos, which gives birth to a new weakly supervised pipeline for downstream long-video tasks. |
|
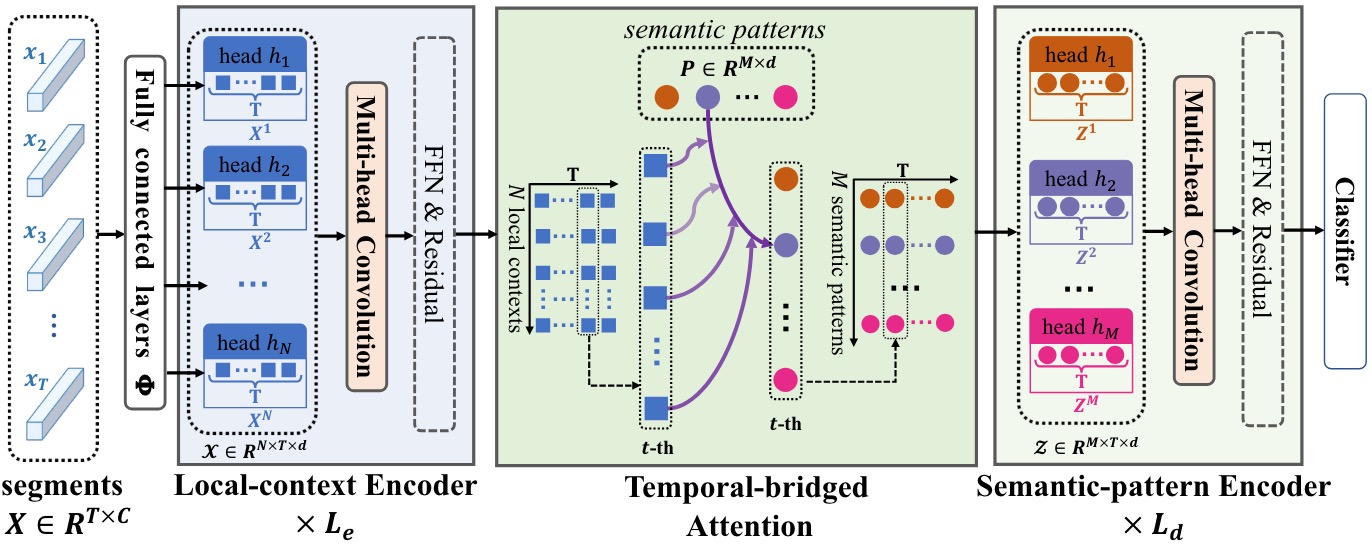
ActionHub: A Large-scale Action Video Description Dataset for Zero-shot Action Recognition
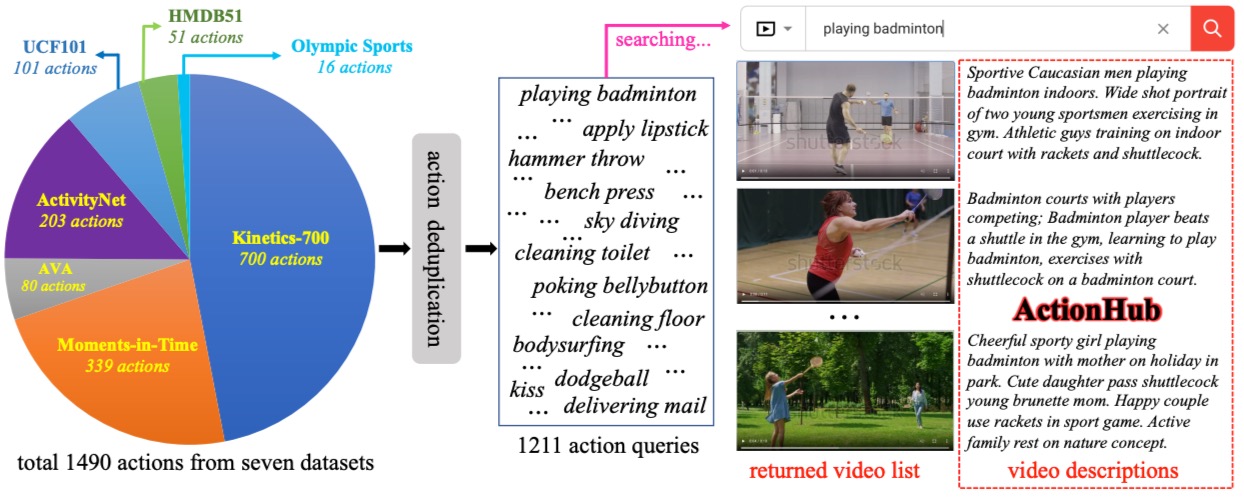
Jiaming Zhou, Junwei Liang, Kun-Yu Lin, Jinrui Yang, Wei-Shi Zheng arxiv, 2024 [paper] [bibtex] A large-scale action video description dataset named ActionHub is proposed, which is the first, and the largest dataset that provides millions of video descriptions to describe thousands of human actions. |
|
TwinFormer: Fine-to-Coarse Temporal Modeling for Long-term Action Recognition
Jiaming Zhou, Kun-Yu Lin, Yu-Kun Qiu, Wei-Shi Zheng Transactions on Multimedia (TMM), 2023 [paper] [bibtex] |
|
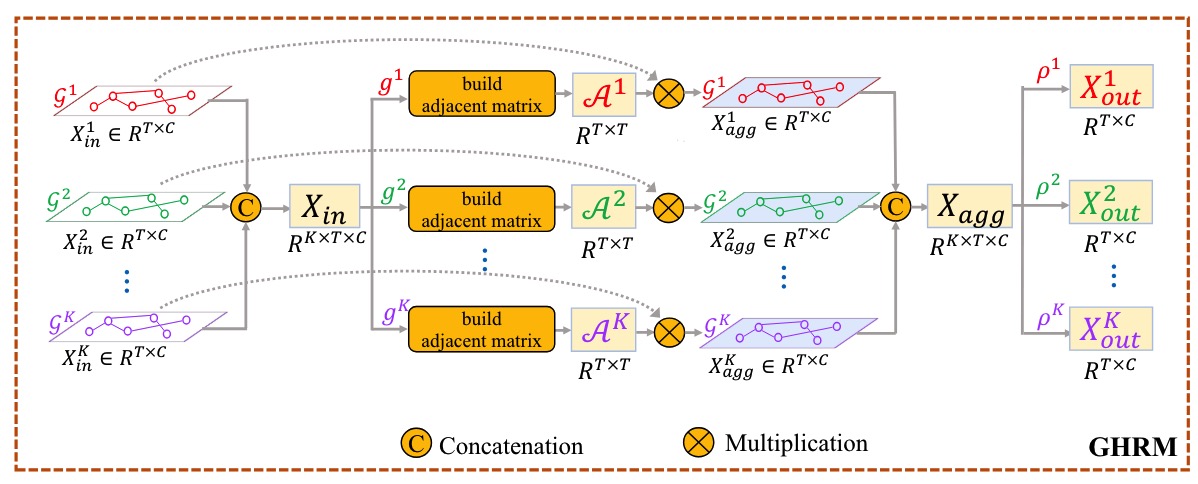
Graph-based High-order Relation Modeling for Long-term Action Recognition
Jiaming Zhou, Kun-Yu Lin, Haoxin Li, Wei-Shi Zheng CVPR, 2021 [paper] [supp] [bibtex] |
|
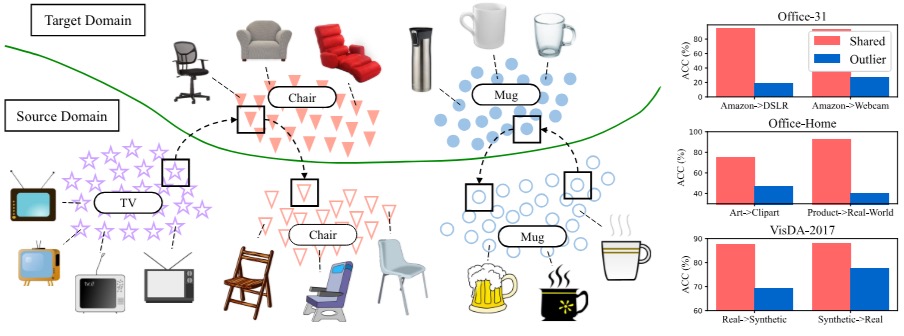
Adversarial Partial Domain Adaptation by Cycle Inconsistency
Kun-Yu Lin, Jiaming Zhou (co-first), Yu-Kun Qiu, Wei-Shi Zheng ECCV, 2022 [paper] [supp] [bibtex] |

|
Human-Centric Transformer for Domain Adaptive Action Recognition
Kun-Yu Lin, Jiaming Zhou, Wei-Shi Zheng TPAMI, 2024 [paper] |
|
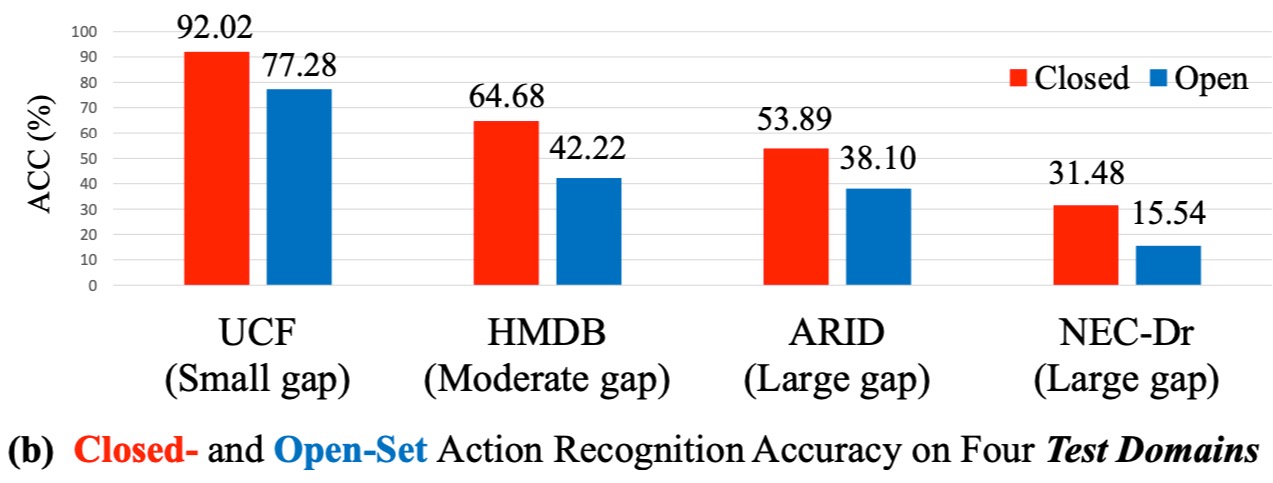
Rethinking CLIP-based Video Learners in Cross-Domain Open-Vocabulary Action Recognition
Kun-Yu Lin, Henghui Ding, Jiaming Zhou, Yi-Xing Peng, Zhilin Zhao, Chen Change Loy, Wei-Shi Zheng arxiv, 2024 [paper] [bibtex] [github] The first benchmark, named XOV-Action, for the cross-domain open-vocabulary action recognition task, and a simple yet effective method to address the scene bias for the task. |
|
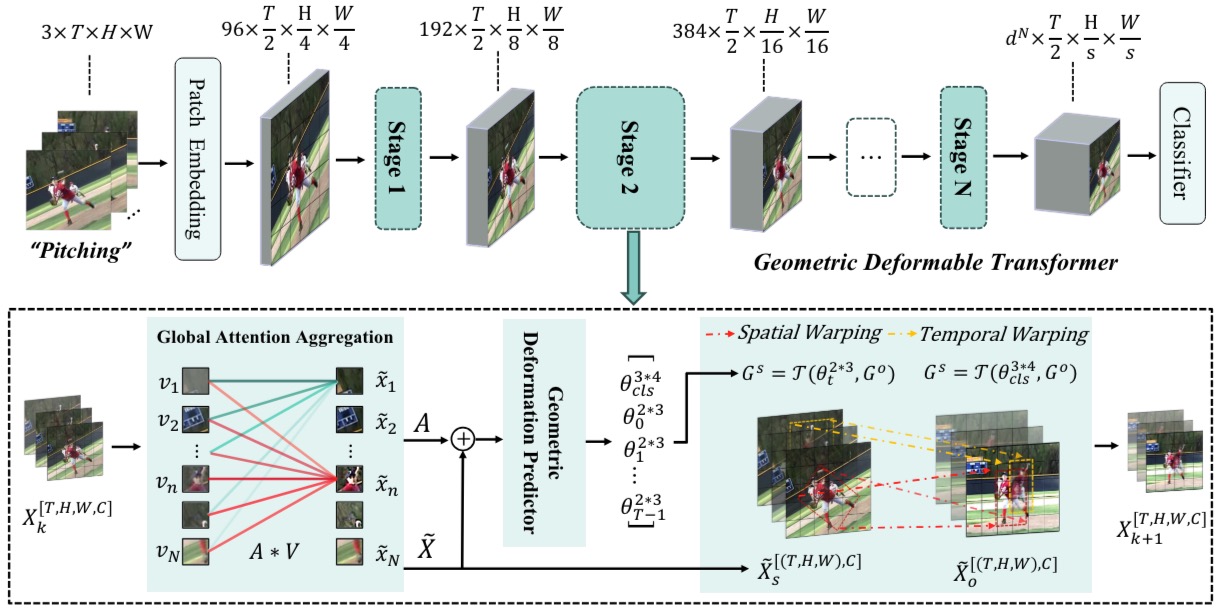
GeoDeformer: Geometric Deformable Transformer for Action Recognition
Jinhui Ye, Jiaming Zhou, Hui Xiong, Junwei Liang arxiv, 2023 [paper] [bibtex] |
|
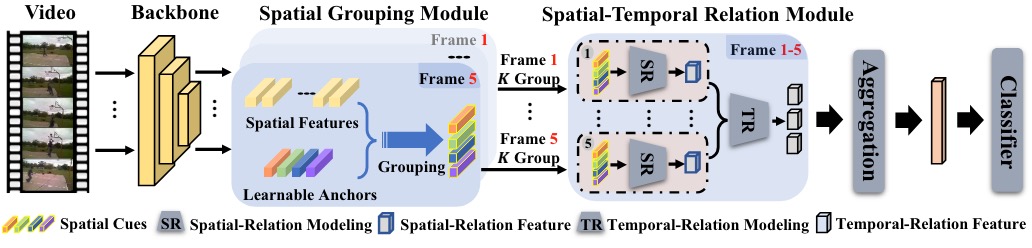
Diversifying Spatial-Temporal Perception for Video Domain Generalization
Kun-Yu Lin, Jia-Run Du, Yipeng Gao, Jiaming Zhou, Wei-Shi Zheng NeurIPS, 2023 [paper] [supp] [bibtex] [github] |
| Reviewers of CVPR 2022-Now, ECCV 2022-Now, ICCV 2023-Now. |
| Reviewers of NeurIPS 2024-Now, ICML 2024-Now, ICLR 2024-Now. |
| Reviewer of Transactions on Pattern Analysis and Machine Intelligence (TPAMI). |
| Reviewer of Transactions on Multimedia. |
| Reviewer of Pattern Recognition. |
|
This website borrows from Jon Barron. |