Motivation
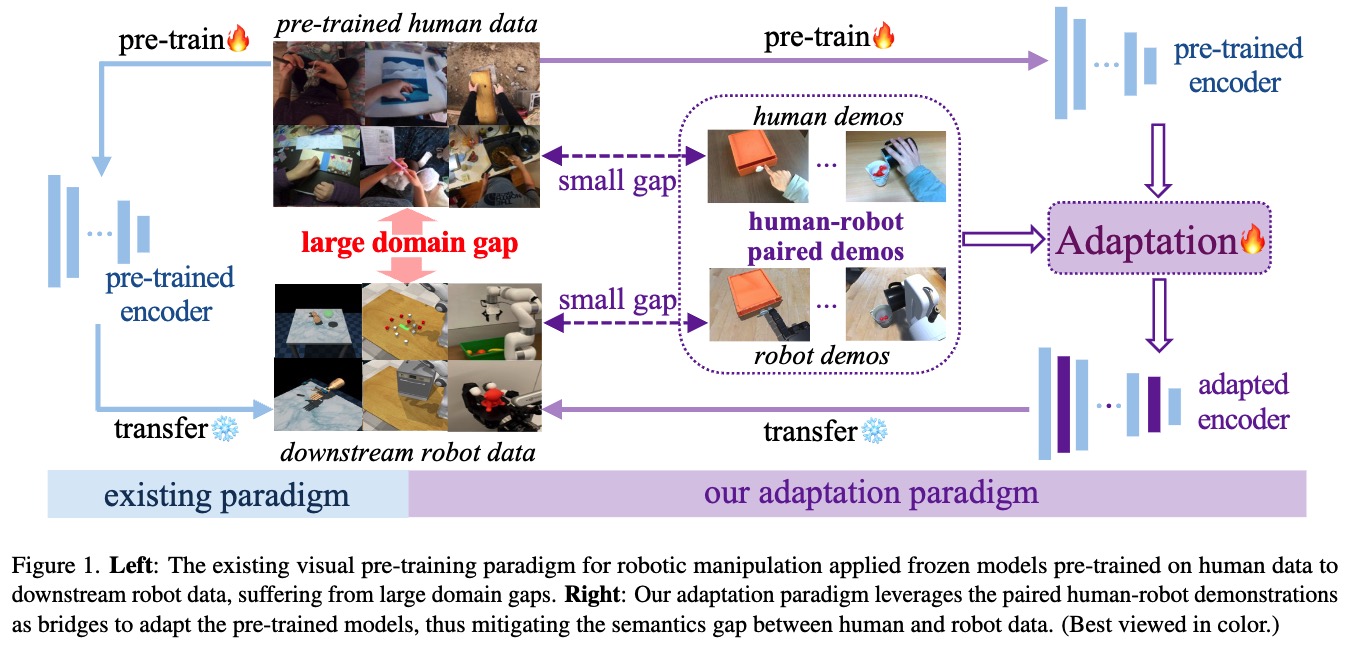
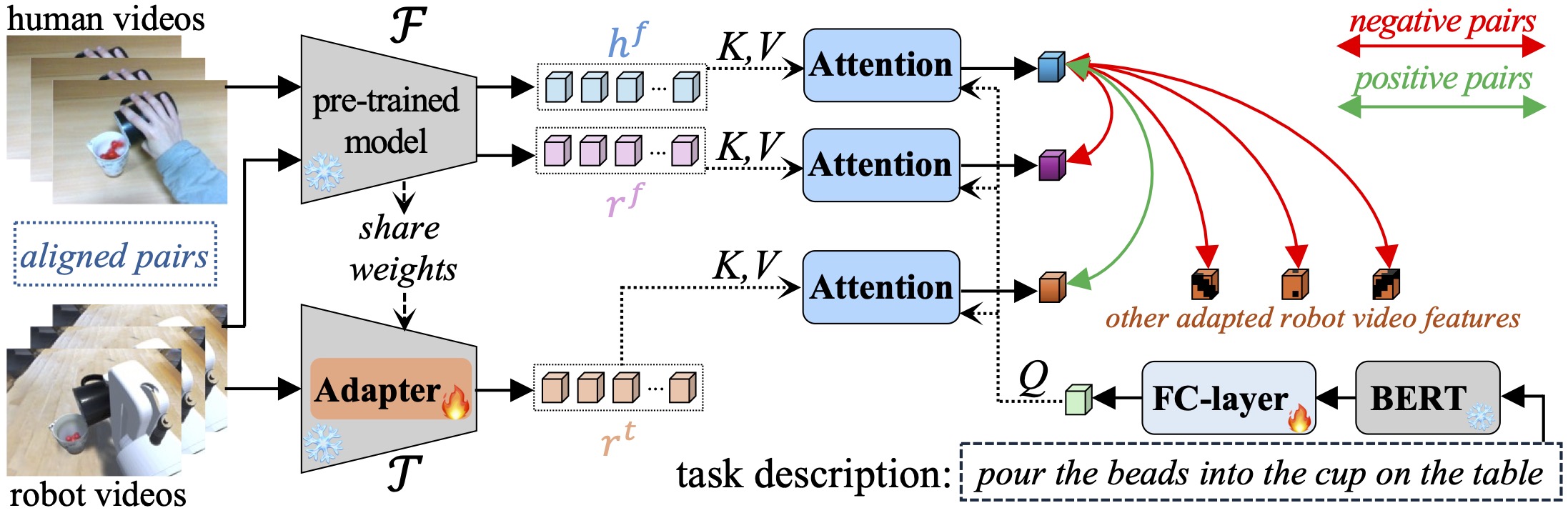
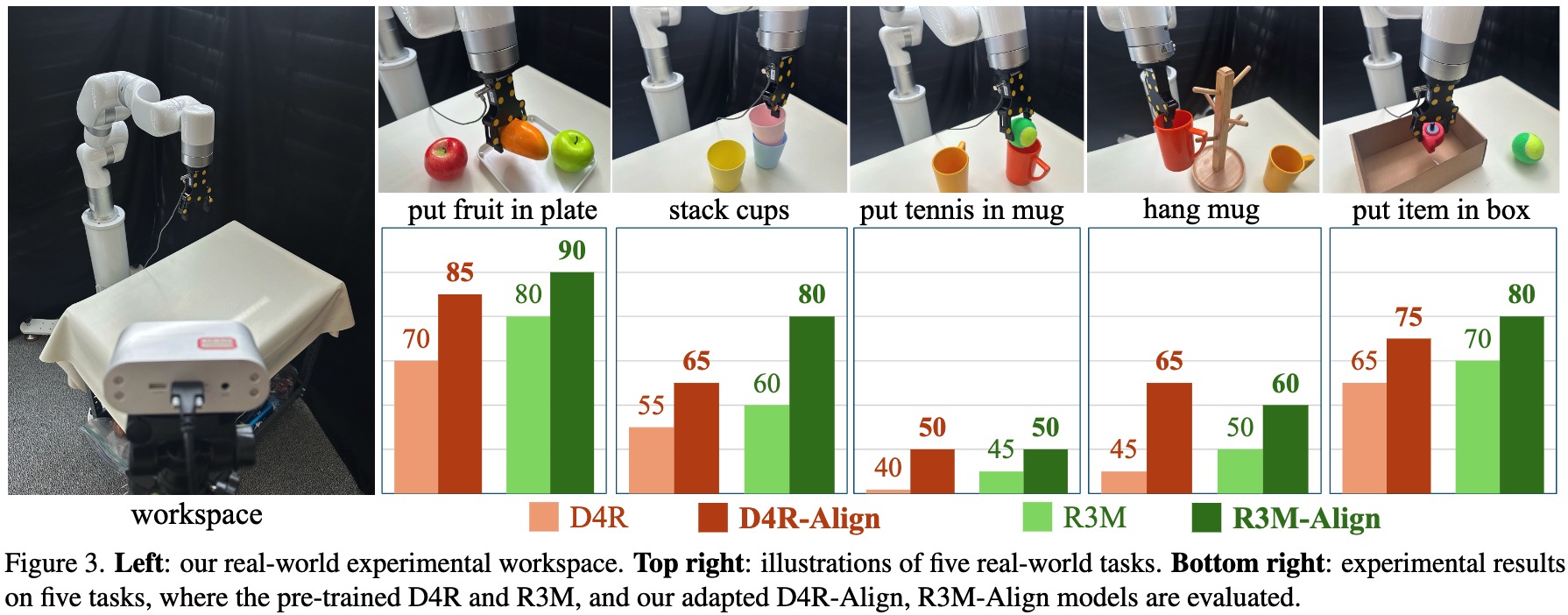
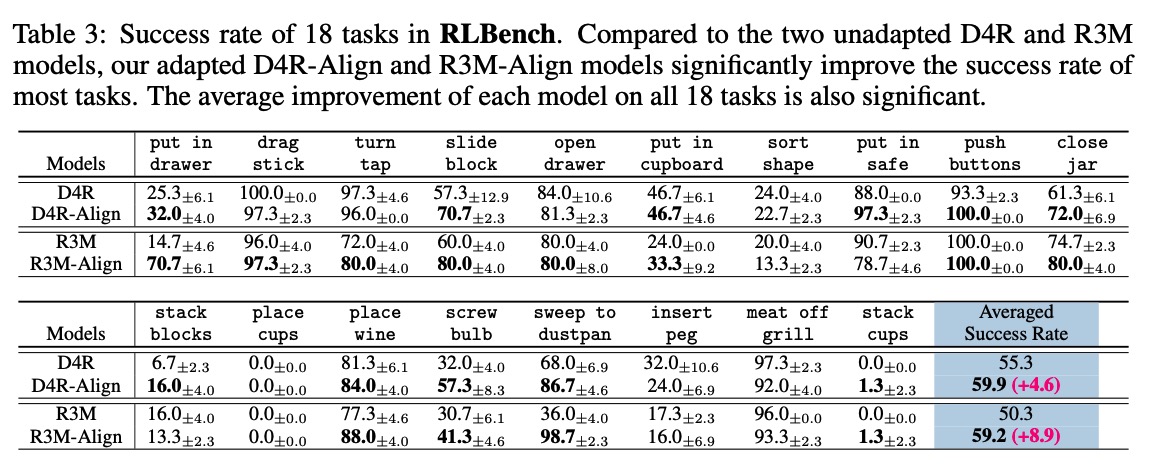
We highlight the human-robot domain discrepancy in visual pre-training for robotic manipulation, and provide a new adaptation paradigm that simultaneously alleviates the domain discrepancy and maintains the versatility of pre-trained models.